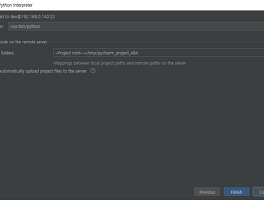
Bigdata (12) 썸네일형 리스트형 NBP Ncloud Cloud Hadoop에서 pySpark로 Object Storage 읽오는 방법 맨날 문서만 만지다가 오랜만에 코드 만지니 재밌네요. 문서질 하면 벌써 뻗었겠지만 코드질 하니 잠이 안오네요. 이번에 프로젝트를 하면서 네이버 클라우드를 처음 사용하는데 생각보다 재미있게 만들었네요 일단 클라우드 하둡을 세팅을 하면 HDP를 포팅해논것 같은데, 일단 Ambari가서 안쓸것 같은 Zepplin, Ozzie 는 다 꺼버리고 일단 NBP가 아쉬운건, 정말 잘만들어놨는데, 설명서가 부족하네요 ..;;(네이버에서 예제코드를 AWS S3 기준으로 설명해놨네여) 다음의 예제는 Pyspark로 Object Storage의 Parquet를 가져오는 예제입니다 2018/11/29 - [Study/Bigdata] - Pyspark로 Spark on Yarn Code --1(개발환경구성) 일단 기본코드는 다움.. Pyspark로 Spark on Yarn Code --1(개발환경구성) Spark로 개발하는 방법에는 여러가지가 있지만, 일단은 PySpark를 사용하고 있습니다 다른 이유보다 너무 쉽게 됩니다. 현재 개발환경은, 개발서버에 Pycham 이 Direct로 붙는다는 환경이고 방화벽등의 환경에서는 달라질수 있습니다 먼저 제 환경은 다음과 같습니다 개발툴 : Pycham Professional - 서버의 파이썬 리모트 인터프리터 사용 - 시스템 기본 파이썬 인터프리터 사용 플랫폼 : HDP(Hortonworks Data Platform) 3.0.1 import os import sys os.environ['SPARK_HOME'] = "/usr/hdp/3.0.1.0-187/spark2" os.environ['HIVE_HOME'] = "/usr/hdp/3.0.1.0-187/hive".. hbase cannot find an existing table / hbase table already exists (zookeeper) 2016/03/08 - [Study/--Hadoop Eco(Apache/HDP)] - hbase table already exists 어제 관련된 몇가지 조치를 하다가 HDFS 내의 HBASE를 날렸는데오 존재하는 테이블이라 나와서 여러가지를 해보았는데, 결론은 Zookeeper에 Table남아있어서 생긴 결과였습니다. 외국 해외포럼에서 찾아보니 좀비 테이블이라고 지칭하는데, 이걸 제거하는 방법은 Zookeeper Server 접속하며서 Hbase 노드에 있는 Table a목록중에 해당 테이블을 제거 하면 됩니다. 이번에 HBASE 쓰면서 느낀건.. 엄청 잘깨진다.. hbase table already exists 지금 상황은 Hbase가 잘못되어서 다시 설치하려는 케이스입니다. HDFS 안에 잇는 Hbase를 지웠는데 테이블을 생성하려고 할때 테이블이 존재한다면, zookeeper 내부에 있는 Table 정보도 지워주셔야 됩니다. 올바른건지 모르겠는데, 아마 다른 방법이 있을것 같은데,, 시간이 없다보니 zookeeper 내부에서 rmr /hbase 하고 hbase 들어가면 주키퍼에 /hbase 가 없다고 나올겁니다.. 저는 이상태에서 콘솔상에서 hbase hbck -fix를 하고 hbase shell로 다시 들어가니 다시 잘되네요 파이썬으로 병렬처리 하기 3 마지막장 (Parallel Python) 오늘 심각한 고민을 했습니다 ... 자바는 그냥 갔다 버려야되나.. Parallel Python 이거 써보고 할말을 잃었습니다. 생각보다 너무 쉽고. Parallel Python을 사용하기 위해서는 대략 다음 절차를 수행하시면 됩니다. 연산을 하려는 노드, Master노드에 Parallel Python 설치(http://www.parallelpython.com/) [현재 저같은경우 Python 2.7을 사용하고 있습니다.] 그다음 연산하려는 모든 노드에서 네트웍 대역이 같다면, ppserver.py -a (이 의미는 실제 코드 설명할때 설명0 그리고 마스터 노드에서 병렬처리할 코드를 작업하시면 됩니다. 큰틀은 다음과 같습니다. 가장 중요한 부분은 ppserver= ppservers=("*",) 입니다. .. 파이썬으로 병렬처리 하기 2 (Parallel Python) 잠깐동안 예제를 따라해보면서 해본 느낌은.. 잘 모르겠지만 엄청 간단합니다. 먼저 Parallel Python에서 http://www.parallelpython.com/content/view/18/32/ 에서 다운 받아서, pp를 다운받아서, 돌아갈 머신과 마스터 노드에 python setup.py install 하면 끝.. 그리고 사용방법은 계산노드(slave)에서 ppserver.py -a(auto discovery) 하면 끝.. 물론 포트를 지정해 준다면 -p 옵션을 사용하면됩니다. 그런다음 마스터 노드에서 다음과 같은 방법으로 하면됩니다. (지금 같은경우는 1master node, 1slave node로 구성된 케이스) import sys,thread import pp class myTest: d.. 파이썬으로 병렬처리 하기 1 (Parallel Python) 몇가지 처리해야할 작업이 있습니다. 몇 가지 케이스에 대해 계속 테스트를 해보고 있지만. 이걸 Hadoop MapReduce로 처리하는것은 정말 성능이 안나오더군요. 흔히 말한는 반복적인 작업... 이걸 Storm, 또는 Spark를 통해 해결해 보고 싶지만. 현재 사정상 신규아키텍처를 도입하는데 문제가 있어서... 물론,,, 현재 환경은 HDP(Hortonworks Data Platform)2.3 이기 때문에, 설치하거나 실행하는데, 문제는 아닙니다. Storm 같은경우 Topology를 만들면 되겠지만.. 약간 제가 생각하는 작업에는 불리할것 같고.. Spark쪽은 아직 제가 지식이 부족해서 시간대비 성과가 부족할것 같은 생각 때문입니다. 물론, 전 아직까지는 언어중에 Java가 좋지만, 요즘 왠만한.. Sqoop 1.4.6 설치, 사용 예제(Migrating data using sqoop from Mysql to HBase) Sqoop2 가 있지만, 1이 익숙한 관계로 다음은 MySQL 에서 Hbase로 Migration 하는 예제 입니다. wget http://mirror.apache-kr.org/sqoop/1.4.6/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gztar zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gzmv sqoop-1.4.6.bin__hadoop-2.0.4-alpha /usr/local/sqoop vim /etc/profile export HBASE_HOME=/usr/local/hbase export SQOOP_HOME=/usr/local/sqoop export PATH=$PATH:$SQOOP_HOME/bin:$HBASE_HOME/bin:$.. 이전 1 2 다음