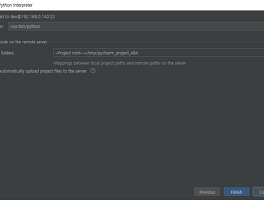
hadoop (41) 썸네일형 리스트형 NIFI could not load known_hosts 해결방법 NIFI에서 ListSFTP 또는 getSFTP를 사용할때 분명히 계정 주소, 포트 까지 잘썻는데 could not load known_hosts 다음과 같은 오류를 내뿜을수 있습니다 저는 제가 잘못쓴건줄 알았는데-, 결론은 리눅스에서 nifi가 동작하는 계정으로 ssh로 한번 접속해주신다음 해주시면 되십니다 다음내용은 관련 포럼에 있는 내용입니다 https://community.cloudera.com/t5/Support-Questions/Using-ListSFTP-results-in-an-exception-Failed-to-obtain/td-p/219081 Re: Using ListSFTP results in an exception: Failed to obtain connection to remote .. NBP Ncloud Cloud Hadoop에서 pySpark로 Object Storage 읽오는 방법 맨날 문서만 만지다가 오랜만에 코드 만지니 재밌네요. 문서질 하면 벌써 뻗었겠지만 코드질 하니 잠이 안오네요. 이번에 프로젝트를 하면서 네이버 클라우드를 처음 사용하는데 생각보다 재미있게 만들었네요 일단 클라우드 하둡을 세팅을 하면 HDP를 포팅해논것 같은데, 일단 Ambari가서 안쓸것 같은 Zepplin, Ozzie 는 다 꺼버리고 일단 NBP가 아쉬운건, 정말 잘만들어놨는데, 설명서가 부족하네요 ..;;(네이버에서 예제코드를 AWS S3 기준으로 설명해놨네여) 다음의 예제는 Pyspark로 Object Storage의 Parquet를 가져오는 예제입니다 2018/11/29 - [Study/Bigdata] - Pyspark로 Spark on Yarn Code --1(개발환경구성) 일단 기본코드는 다움.. Pyspark로 Spark on Yarn Code --1(개발환경구성) Spark로 개발하는 방법에는 여러가지가 있지만, 일단은 PySpark를 사용하고 있습니다 다른 이유보다 너무 쉽게 됩니다. 현재 개발환경은, 개발서버에 Pycham 이 Direct로 붙는다는 환경이고 방화벽등의 환경에서는 달라질수 있습니다 먼저 제 환경은 다음과 같습니다 개발툴 : Pycham Professional - 서버의 파이썬 리모트 인터프리터 사용 - 시스템 기본 파이썬 인터프리터 사용 플랫폼 : HDP(Hortonworks Data Platform) 3.0.1 import os import sys os.environ['SPARK_HOME'] = "/usr/hdp/3.0.1.0-187/spark2" os.environ['HIVE_HOME'] = "/usr/hdp/3.0.1.0-187/hive".. HDP3 클러스터에 HDF(nifi)설치 HDP3 되면서, 많은것이 바뀌었습니다 일단 눈에 띄는 변화는 Hadoop3 이 들어갔다는것과 제눈에 볼때 딱 달라진건 Falcon 이 없어진것 그리고 Flume 이 없어졌다는 https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.6.3/bk_release-notes/content/deprecated_items.htmlDeprecated Components and Product CapabilitiesThe following components are marked deprecated from HDP and will be removed in a future HDP release:Component or CapabilityStatusMarked Deprecated as .. intellj, Spark Assembly 스파크 스트리밍 코드를 묶다가 예전에 있던 코드를 활용했더니 ... [warn] ::::::::::::::::::::::::::::::::::::::::::::::[warn] :: UNRESOLVED DEPENDENCIES ::[warn] ::::::::::::::::::::::::::::::::::::::::::::::[warn] :: com.eed3si9n#sbt-assembly;0.11.2: not found[warn] ::::::::::::::::::::::::::::::::::::::::::::::[warn][warn] Note: Some unresolved dependencies have extra attributes. Check that these dependencies exist with .. HDFS 노드 추가 및 삭제 HDP에 익숙해져있다가 self-deployed Hadoop을 사용하다 보면, 답답할때가.... 예를들면, HDFS를 확장하는것조차 마우스 클릭 딸각한번으로 해결될 문제가. 메뉴얼로 정리해보면 1.Hadoop.tar.gz 파일을 확장하려는 노드로 배포 데이터 노드에서 ./hadoop-daemon.sh start datanode 2. 네임 노드(HA했다면 둘다 설정 복사)에서 hdfs-site.xml에서 설정한 파일을 참고해서 dfs.hosts /etc/hadoop/dfs.hosts dfs.hosts.exclude /etchadoop/dfs.exclude dfs.hosts에 호스트 파일에 새로 추가한 데이터 노드 추가 3. Acitve NameNode에서 ./refresh-namenodes.sh 노드 추가.. Spark 에서 Parquet 저장할때 GZ 말고 Snappy 사용법 Spark에서 paruqet 압축 알고리즘을 찾다가. 분명히 두가지 방법중 한가지 방법이면 된다고 하는것 같은데 sqlContext.setConf("spark.sql.psqlContext.setConf("spark.sql.parquet.compression.codec", "snappy")sqlContext.sql("SET spark.sql.parquet.compression.codec=snappy") 저는 이것이 동작하네요 sqlContext.sql("SET spark.sql.parquet.compression.codec=snappy") 사용하는 화경은 HDP 2.5 Spark 1.6 입니다 zeppelin 1.7.1 with hive interpreter 맨날 HDP 에 설치가 잘된 제플린을 사용하다보니,, 수동으로 제플린을 사용하려고 하니 HIVE를 사용하려고 하니 다음과 같은 오류가 발생합니다. Prefix not found. paragraph_1493986135331_752263516's Interpreter hive not foundorg.apache.zeppelin.interpreter.InterpreterException: paragraph_1493986135331_752263516's Interpreter hive not found at org.apache.zeppelin.notebook.Note.run(Note.java:605) at org.apache.zeppelin.socket.NotebookServer.persistAndExecuteS.. 이전 1 2 3 4 ··· 6 다음